本文共 3312 字,大约阅读时间需要 11 分钟。
当我们设计复杂系统时,生产环境系统的可观察性是必须的。有人说能够监控生产环境中的系统比在开发过程中测试它的所有功能更重要。对我来说,它们不是真正可以进行比较的东西,你也不能放弃其中之一。
传统上,如果组织中有IT 运维部门,可能会有人使用Nagios 等工具进行黑盒监控。这个工具给你一些信号,如系统停机、服务器/服务停机、CPU 消耗高等。这是必须的,非常有利于识别问题的症状,但没法知道根本原因。
一旦你得到的症状告诉你有什么不对劲。你需要深入了解并理解根本原因。这个时候需要用到白盒监控。白盒监控可以帮助你确定问题的根本原因,更重要的是,如果设计正确,可以通过查看系统上的某些趋势,对于可能出现的可预防问题,为你提供主动告警。因为应用程序的内部可以提供更有价值和可操作的告警,使得对边界场景和类似性能问题采取行动时更加主动,并在问题发生之前采取行动。
白盒监控还包括日志记录、度量和分布式跟踪,它们指的是一类使用系统内部报告的数据的监控工具和技术。我想写一下白盒监控范围内可观察性的这三个支柱。当正确使用这些工具时,通常你可能就不需要进行黑盒监控了,但如果你问我,继续进行黑盒监控当然很好。
- 日志
- 度量
- 分布式跟踪
他们之间有何不同之处以及我们如何通过这三个支柱实现这一基础。
日志
大多数我曾经工作过的系统都实现了这一支柱。
日志是系统中发生的事件,是来自系统的详细的优先级消息。我认为将系统中的日志作为事件不是一个坏主意。
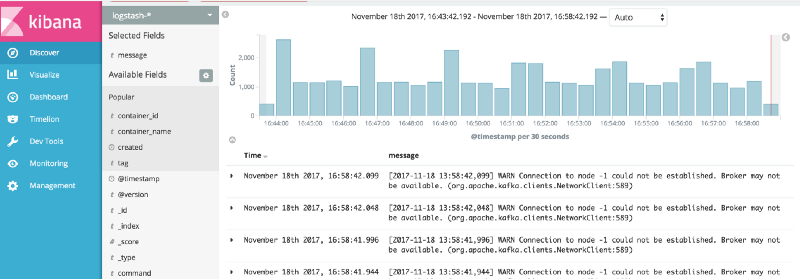
日志最大缺点是处理、存储和运输的成本高。它们包含发生在系统中的每个请求的数据。如果你在数百台服务器上运行应用程序,则需要将它们小心地汇聚到一个中心位置,否则无法在每一台服务器上查看它们。就像你可能知道的,ELK 是最常见的技术栈。
另外将所有的日志集中到一起也有一些缺点。如果你正在处理大量流量,你可能需要考虑要发送什么,不发送什么(提示:正确的日志记录级别),你还需要有一个合适的聚合集群,大多数情况下是Elasticsearch 集群。拥有一个Elasticsearch 集群来聚合所有日志却在黑色星期五这样出现日志峰值的日子里出现故障,这种情况并不少见。
类似SLF4J、log4j、log4net 这样的库(根据你所使用的技术栈有很多选项)用于创建格式化的纯文本日志。最常见的应用程序日志传送方式是将它们写入到磁盘上的文件,然后使用FileBeat 等工具将它们发送到ELK。但是应用程序也可以将日志直接发送到日志聚合器。有很多选项,你可以根据自己的情况评估。我曾经开发了一个log4net appender,它将日志作为消息推送到ampq(我们使用RabbitMQ),然后我们使用Logstash 从RabbitMQ 接收日志并将它们写入到elasticsearch 中,并使用Kibana 进行可视化。
最近我们开始使用Docker Engine 来发送我们的日志。Docker 添加了一项功能,将日志发送到中心日志存储库,如ELK 技术栈。我知道的大多数中央日志存储库都支持Graylog 扩展日志格式(GELF),我想这就是。
你还可以从基础设施工具中获取日志。大多数流行的消息代理(如kafka、RabbitMQ、nsq)、HTTP 反向代理、负载均衡器、数据库、防火墙、应用程序服务器、中间件都提供了日志,你可以将它们发送到中心日志聚合器。
度量
度量作为时序数据,是跨时间间隔的可聚合和测量的数字。度量针对存储和数据处理进行了优化,因为它们只是一段时间内聚合的数字。
基于度量的监控的一个优点是度量生成和存储的开销是恒定的,它不像基于日志的监控那样,与系统负载的增加成正比,随之改变。这意味着磁盘和处理利用率不会根据流量的增加而改变。磁盘存储利用率仅根据时序数据库上存储的数据而增加,当你在应用程序代码中添加新指标或启动新服务/容器/主机时,才会发生这种情况。
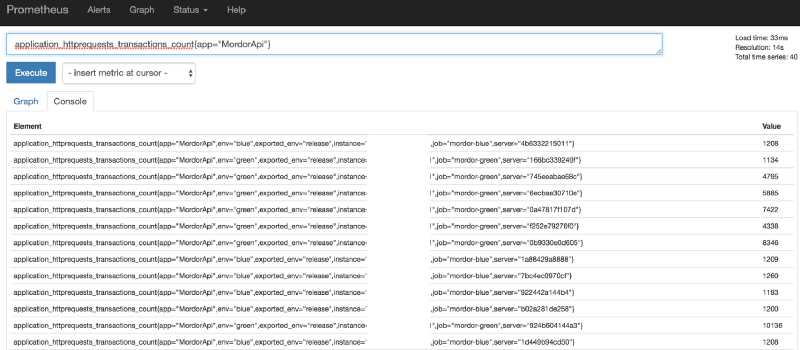
Prometheus(p8s)客户端不会将每个度量发送到p8s。常见的prometheus 客户端,例如流行的Coda Hale 库(它是java 项目,但是也支持不同语言),在应用程序进程中聚合时序数据,并在进程内计算生成度量输出。
因此,如果要开始使用Prometheus 从应用程序中收集指标,首先需要向应用程序代码添加采集器。你可以在p8s 网站上找到。Prometheus 基于pull 工作,基本上你可以使用其中可用的一个收集应用程序中的指标,然后在应用程序中通过HTTP 对外开放,通常是应用程序中的/metrics 端点。最后配置prometheus 每隔几秒从应用程序中收集指标。
度量比查询和聚合日志数据更有效。但是日志可以提供准确的数据,如果你想获得服务器响应时间的准确平均值,你可以记录它们,然后在elasticsearch 上编写聚合查询。度量不是百分之百准确,而是使用一些统计算法。类似Prometheus 和常见的度量客户端这些工具实现了一些高级算法,以便为我们提供最准确的数字。别误会,我不是说使用日志,我是说正确的使用日志和度量。
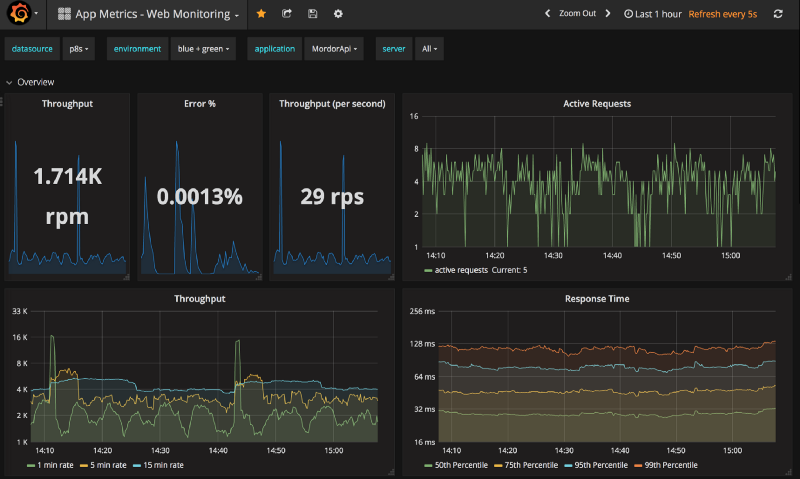
在Prometheus 中收集所有指标后,你可以使用Grafana 可视化这些指标。
我应该收集什么?
一旦你配置了自己的收集策略,这是你需要回答的问题。如果要为微服务添加度量;
首先,我建议你捕获请求数,以观察你的服务有多繁忙以及每秒/分钟收到多少请求,即请求数。
其次,捕获服务的服务时间。本质上是每个请求的持续时间,来捕获服务的延迟,即服务响应时长。
然后,捕获错误请求的数量,以观察请求服务失败的百分比,即请求错误率。
最后,如果你不确定要检查的百分位数,将其设置为95%百分位数。如果你想欺骗自己,平均时长或平均值是皆大欢喜的。
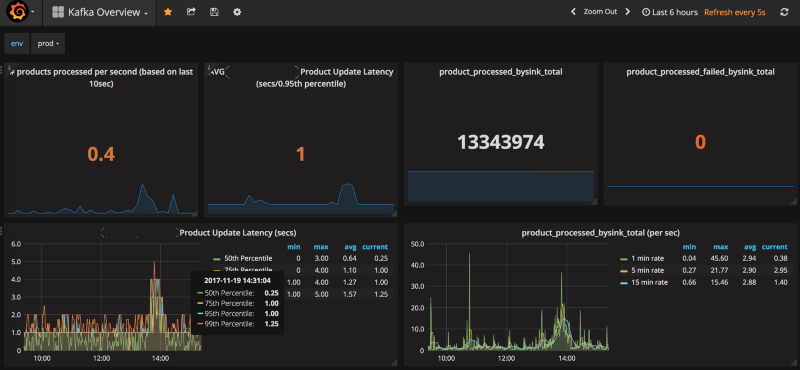
你的应用程序会有非常具体的案例,这些只是对你开始考虑的一些建议。例如,在我们上一个项目中,我们想要测量每个产品的ETL 处理时间。我们在底层系统中捕获了每个产品的更新速度,并计算到达ETL 管道末尾所花费的时间。通过这种方式我们想看看基于Kafka 的数据流管道是否存在瓶颈。我们可以观察数据流管道的每个阶段,以确定瓶颈,并在需要时提供新的Kafka Streams 容器或Kafka Connect 容器。
应用程序监控需要日志和度量,并且需要由你自己的团队去构建,而不是IT 运维团队。日志可以让你深入了解每个请求,并查找在特定时间发生的具体事件的详细信息,而指标可以向你显示上下文并了解系统中的趋势。
分布式跟踪
日志可以让你了解特定时间发生的情况,但在构建分布式系统时仍然很难将它们关联起来。特别是在微服务时代,客户的请求可能会导致应用程序中出现数百种不同的服务调用。
通过日志很难监控超过预期时长的调用、失败的调用,以及为什么会调用失败。你可以通过唯一请求ID 查找匹配的日志,但查询客户所面临的最慢的调用仍然很困难。
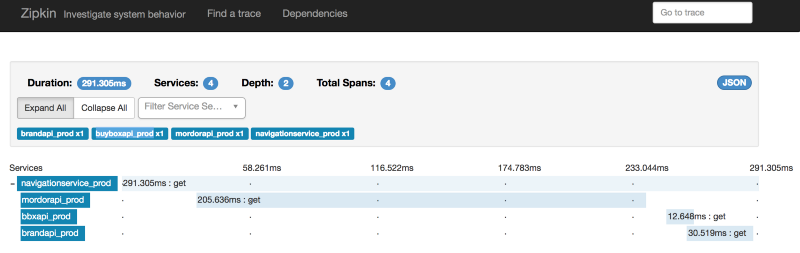
因此,如果你处于微服务领域并致力于分布式系统,你可以想象服务之间相关联的分布式调用的可视化是多么有价值。我在早年尝试过Zipkin,它并不容易配置,但现在是容器时代,只需要一条命令。不过不是每个人都在使用它。 作为所有OSS 项目的唯一标准,可以让你的应用程序代码不依赖于特定的跟踪供应商。
现在,你可以使用的开源客户端,并将跨度信息发布到支持的(、、Appdash、LightStep、Hawkular、Instane 等)。
如果你还记得浏览器的开发人员工具并在网络选项卡中检查正在发起哪些请求,它可以让你非常了解浏览器在做什么,哪些请求是并行产生的,哪些花费太长时间处理而让客户等待。分布式跟踪器为你在服务端提供类似的可视化。
例如,你可以看到哪些服务正在被调用,哪些服务花费的时间比预期要长,你接收到的获取指定类别的产品列表并按照价格排序的请求有哪些失败了。
Zipkin 接口可以让你查询最长和最短耗时的调用栈。这样你可以关注性能低的调用,了解系统的哪个部分是瓶颈。你还可以可视化服务之间的依赖关系,当你有数百个系统相互通信时,这会变得非常有价值。
英文原文:
转载地址:http://ctnlx.baihongyu.com/